Reduced Bit-Width Instruction Set Architecture
Challenge
Code size is an important constraint for many embedded systems, especially the ones in which the code is burnt on ROMs, which can be the major component on the chip. Dual instruction set, one composed of full width instructions, and another composed of narrow instructions is a promising approach to reduce code size. Our research efforts are towards developing tools and techniques to compile for such reduced bit-width Instruction Set Architectures.
Code Size Problem in Embedded Systems
Programmable RISC processors are increasingly being used to design modern embedded systems. Examples of such systems include consumer electronics items, e.g., cell phones, printers, modems etc. Using RISC processors in such systems offers the advantage of increased design flexibility, high computing power and low on-chip power consumption. However, RISC processor systems suffer from the problem of poor code density which may require more ROM for storing program code. As a large part of the IC area is devoted to the ROM this is a severe limitation for large volume, cost sensitive embedded systems.
reduced bit-width Instruction Set Architecture (rISA)
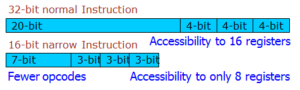
reduced bit-width ISA is an architectural feature in which the processor has two instruction set, one is composed of the normal 32-bit wide instructions, while the other has narrow 16-bit wide instructions. If the application can be expressed only in terms of narrow instructions, then 50% code compression can be achieved. Many embedded processors, including ARM-Thumb, MIPS 32/16 bit TinyRISC, ST100 and the ARC Tangent A5. Processors with rISA dynamically translate (or decompress, or expand) the narrow rISA instructions into corresponding normal instructions. This translation usually occurs before or during the decode stage. Typically, each rISA instruction has an equivalent instruction in the normal instruction set. This makes translation simple and can usually be done with minimal performance penalty. As the translation engine converts rISA instructions into normal instructions, no other hardware is needed to execute rISA instructions. Using rISA optimizes the fetch power of the processor also. This is because, fetch-width of the processor being the same, the processor when operating in rISA mode fetches twice as many rISA instructions (as compared to normal instructions) in each fetch operation. Thus while executing rISA instructions, the processor needs to make lesser fetch requests to the instruction memory. This results in a decrease in power and energy consumption by the instruction memory subsystem.
Challenges in using rISA
Although the theoretical limit of code size reduction achievable by rISA is 50\%, severe restrictions on the rISA IS severely limit the compiler capability to achieve so. The rISA IS, because of bit-width restrictions, can encode only a small subset of the normal instructions. Thus not all normal instructions can be converted into rISA instructions, and sometimes more than one rISA instruction may be the equivalent of one normal instruction. As a result indiscriminate conversion to rISA instructions may result in an increase in code size. Again, due to bit-width restrictions rISA instructions can access only a restricted set of registers. For example, the ARM-Thumb allows access to 8 registers out of 16 general purpose ARM registers. As a result indiscriminate conversion of normal instructions to rISA instructions may result in register spilling, and thus degradation in performance and increase in code size. Furthermore, several options available in normal IS like predication and speculation may not be available in the rISA mode. Such severe restrictions on the rISA IS make the
code-size reduction obtainable by using rISA very sensitive to the compiler quality, the application features and the rISA Instruction Set itself.
Our Approach
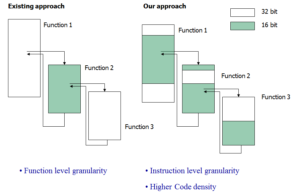
One of the key features of our code generation for rISA is that we perform the switch between the normal instructions and rISA instructions at a instruction-level granularity, rather than at the function-level granularity, as done in previous approaches. This allows us to avoid the parts of a function that are not-profitable to convert to rISA, or pick only the parts of function that are profitable to convert to rISA. The other important aspect of our approach is that for each region of code that we choose to convert, we use a register pressure heuristic to estimate if converting the region of code will be profitable or not. No previous approach considered the effect of register pressure in deciding whether to convert a region of code to rISA or not. Very often it happens that the register pressure in the selected region is so high, that it leads to code size increase due to extra spill code. Using register pressure in the decision to convert allows us to avoid the regions that will lead to code size increase. As a result we get consistent 33% code compression.