

Challenge
During execution, a processor is typically stalled for a significant amount of time doing nothing, but waiting for data from memory. However, these stall durations are typically small. Our research in this area is to aggregate these small but several stall cycles to create a larger stall, during which the processor can be switched to a lower-power mode.
Many, but small processor stalls
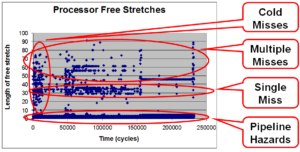
Figure on the right plots the lengths of processor stalls over the execution of the qsort application from the MiBench benchmark suite running on the Intel XScale processor. Very small stalls (few cycles) represent processor stalls due to pipeline hazards, but a lot of stalls are approximately 30 cycles in length. This reflects the fact that the memory latency of the Intel XScale is about 30 cycles. An important observation from this graph is that although the processor is stalled for a considerable time (approximately 30% of the total program execution time) the length of each processor stall is small. The average length of a processor stall is 4 cycles, but none of them is greater than 100 cycles.
Stall – an opportunity for power optimization?
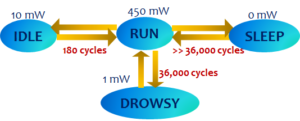
A processor stall, theoretically is an opportunity for optimization. System throughput and energy can be improved by temporarily switching to a different thread of execution, or the energy consumption of the system may be reduced by switching the processor to a low power state. Next figure shows the power state machine of the Intel XScale processor. In the default mode of operation, the XScale is in RUN state, consuming 450mW. XScale has three low power states: IDLE, DROWSY, and SLEEP. In the IDLE state the clock to the processor is gated, and the processor consumes only 10mW, but it takes 180 processor cycles to switch to and back from the IDLE state. However, no naturally occuring processor stall is more than 100 cycles, therefore there is no opportunity to reduce the power consumption.
Prefetching can make memory activity continuous

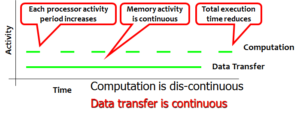
When a memory-bound application executes on a processor, both the processor activity and the memory-bus activity is discontinuous. This is because sometimes, the processor is waiting for data to return from the memory, while at other times, the memory is waiting for the processor to request for new data. If we do pre-fetching, i.e., request the data for the next set of iterations in the current iteration, then the memory-bus activity can be made continuous, but the processor activity is still discontinuous. This is because the loop is memory-bound, implying that the time it takes to get data from memory is more than the time it takes to compute on it.
Processor Stall Aggregation
What is want is to aggregate all the processor activity into one continuous chunk. This can be achieved through large-scale prefetching. If we can know what data is needed by the loop, then the processor can make a large-scale prefetch request for that data, and then go to sleep. At some point of time, the processor wakes up, and starts working on the data, so that it finishes at the same time, as the last peices of the data are coming.
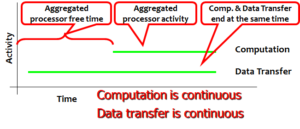
Our approach to achieve this kind of execution requires support both from hardware and software. A small prefetch engine is required, which is programmed with what to prefetch, and it keeps issuing memory requests on the address bus while the processor sleeps. At the right time, so as not to cause any performance overhead, the prefetch engine wakes up the processor. The cache must be active even though the processor is in the sleep mode. We were able to aggregate upto 50K cycles of processor activity by aggregation. And by switching the processor to low-power state, we estimate that upto 20% energy can be saved.