CSE 420 – Computer Architecture 1
“It (Computer Architecture) is not a deary science of paper machines that will never work.
No! It’s a discipline of keen intellectual interest, requiring balance of marketplace forces to
cost-performance-power, leading to glorious failures and some notable successes.”
– John Hennessy and David Patterson.
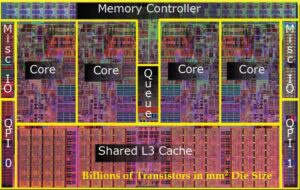
Chip Layout of Modern Many-Core Processor Die (Courtesy: Intel)
Overview
From personal electronic devices to servers, data centers, and supercomputers, the need for architecting better computer systems is inevitable. Especially, the detailed study of the evolution of the computer architecture and deep understanding of – fundamental philosophies involved in the software and hardware elements of the computing systems and their engineering trade-off is required. To hit the spot, this Computer Architecture course starts with bridging the gap between the high-level programming languages (e.g. C/C++, Java, Perl, Python) that we so conveniently use, and the low-level electronic components (e.g. transistors, AND/OR gates, multiplexors). The course then delves into details of designing a processor. The class is divided into 4 modules, i) A simple processor design, ii) Pipelining and ILP, iii) Memory Organization iv) Multi-core processors. Starting from a simple design, we strive to make it better. We learn several fundamental techniques, like pipelining, caching, and parallel execution, which enable the modern computing-based world. Although this course takes the MIPS architecture as a vehicle to explain the complexities and tradeoffs in computer architecture, the concepts are applicable in a much broader scope. The course takes a hands-on approach to understanding computer architecture. It also catapults the experience of developing simulators to model and thereby enriching the understanding of the architecture.
Main Topics
To visualize the landscape of today’s processor design, the pathway is traversed beginning with understanding basic blocks of both – programs and processor design as follows:
i) Which assembly instructions my program translates to and how they execute on a non-pipelined processor? At first, we need to understand the instruction-set architecture of the processor and need to determine that which assembly instructions my program should contain or how does the pointers or data structures are translated to the assembly instructions? Then, we proceed further determining what components processor design need to execute the instructions and how does it work for a non-pipelined MIPS processor. It also helps to understand clearly why it is a hardware-software interface. This altogether establishes the baseline with fundamental details about a microarchitecture upon which other design enhancements can be built.
ii) How does pipelining a processor help and how to mitigate the impact of the resultant hazards? One apparent way to improve processor cycle time is to pipeline it which can boost up the performance but it does not come for free. It brings with it the structural, data and/or control hazards. To gain a better understanding, it is important to analyze the assembly programs in terms of scheduling the instructions through a pipeline and to see stalls of how many cycles is yielded by such hazards. Then, we strive to find an alternative to mitigate the impact of these hazards such as data forwarding by adding bypasses, employing static/dynamic branch prediction, using predication techniques or smart instruction scheduling through compilers, alternating the microarchitectural components in the pipeline etc.

Broadcom’s Vulcan CPU microarchitecture
iii) Out-of-Order Execution: Just the fact that you can pipeline processor does not mean that dramatic speed-ups can be achieved as due to the hazards, we have to stall the pipeline and even issuing (and thus execution) of the independent instructions need to be stalled. So, how do you allow the out-of-order execution (and thus out-of-order-commit) when the multiple functional units are available for the execution? We start with studying register scoreboarding – a pioneer design approach which allowed correct out-of-order execution of the programs even in the presence of write-after-read or write-after-write dependencies among instructions. After analyzing and understanding the pitfalls of scoreboarding, we study how register renaming can help overcoming such false dependencies and we learn that how Tomasulo’s algorithm can help achieving further performance. We end up this module with speculative execution and understanding the need of employing Re-Order Buffer (ROB) to ensure in-order commit yet with out-of-order execution.
iv) How to conquer with caching techniques over hitting a memory wall? Historical perspective on past designs informs us that improvements of high-performance design solutions can be masked by the unavailability of the data. We start with understanding cost-area-power-latency tradeoff for different levels of memory hierarchy and realize the significance of caches in reaping the performance benefits by today’s processors. We study different cache configurations and realize their impact in terms of performance vs. energy trade-off. We also learn the virtual memory system and determine how the address translations happen and what is the role of translation lookaside buffer (TLB).
v) Why aggressive uniprocessor scaling/design optimizations is not enough and the multi-core era: We realize that aggressive transistor scaling or uniprocessor design optimizations cannot be just enough and it hits the power wall. Then, we study the promise of multi-cores and the challenges that multi-core programming put forth against us. Fundamental challenges are sharing and updating the data correctly, synchronization, task scheduling etc. We also study how data-level parallelism such as vectorization or single instruction multiple data (SIMD) can help in accelerating the massively parallel workloads. We conclude with inefficiencies of such approaches, catching glimpse of – what’s next or recent research trends.
Projects
A very important aspect of the course is the projects. Although the modules deliver the fundamental ideas behind latest design philosophies, it is very important that students gain hands-on experience with programming and realizing the role of various micro-architectural components in today’s simulators. Usually, there are four to five projects offered in the course and they make use of MARS simulator (for MIPS assembly programming) and gem5 (cycle-accurate processor simulator popular in academia and supported by the industry). The projects are:
- Writing MIPS programs to achieve the functionality of given C/C++ code.
- Understanding gem5 and simulation of instructions with various CPU models.
- Understanding the impact of microarchitecture parameters (e.g. cache configuration) on numerous benchmarks and analyzing their energy cost vs. performance tradeoff.
- Implementing branch predictors.
- Implementing advanced cache replacement or insertion policies and analyzing their impact.
- Programming for multi-cores (SMT/SPMD).
Learning Outcomes
This course help gaining an understanding of the fundamentals of computer architecture. After doing this course, students will be able to:
- Understand the role and importance of assembly language.
- Understand implementation of a simple pipelined processor.
- Understand the promise, and effects of pipelining. Students will be able to know the basic challenges of pipelining and will have fundamental knowledge on how to resolve those challenges and achieve high performance with pipelining.
- Understand branch prediction, and bypassing.
- Understand that there are limits to parallelism, and just increasing the number of functional units (or ALUs) will not increase processor performance.
- Understand the concept of caches, and know the fundamental mechanism of how they work, and why they are so effective.
- Understand the need, importance and basic implementation of virtual memory.
- Appreciate the need for multi-core processors.
- Have a general idea of the landscape of multi-core processors.
- Realize the programming challenges brought forth by multi-core processors.