Software Managed Manycore (SMM)
Multicore with Software Programmable Memory
Multi-cores provide a way to continue increasing performance, without much increase in the power consumption of the processor. One major challenge in developing multi-core architectures is scaling the memory hierarchy. Maintaining the illusion of a single unified memory in hardware is becoming infeasible. This is because: first, that the power and performance overheads of automatic memory management in hardware (i.e. by caches) is becoming prohibitive, and second, that cache coherency protocols do not scale to hundreds and thousands of cores.
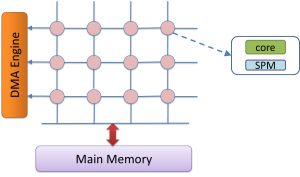
Software Managed Manycore (SMM) architectures are scalable multi-core designs that employ Software Programmable Memory (SPM) in each core — the more power-efficient alternative of caches. The above figure shows an example of SMM architectures. SMM processors can only access code and data that are current on their local SPM. That is to say, the data movement between the close-to-processor memory and the main memory has to be done explicitly in software — typically through the use of Direct Memory Access (DMA) instructions. Our research objective is to develop compiler technology to automatically compile applications for these architectures with memory transfer requests automatically inserted at proper program points and make them usable.
Challenges
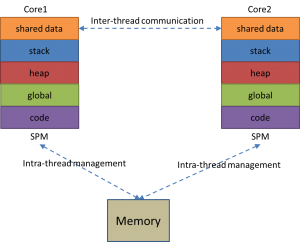
Multi-threading is a popular way to fully make use of the capability of manycore processors for parallel computing. To be able to run multi-threaded applications, both intra-thread code and data and inter-thread communication should be managed, as the below figure shows. Early efforts rely in application developers to insert data management (DMA) instructions by hand for programming SPM-based architectures. However, with the increasing complexity of embedded software, as well as the diversity of the underlying architectures, automated techniques are required to understand the application and insert data management instructions automatically.
Our Approach: Completely Automated Memory Management based on Compilers
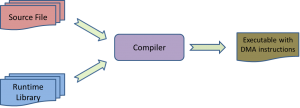
While automatic insertion of data management instructions may be achieved in different ways,—statically by programmers or the compiler, or dynamically through runtime systems that execute additional instructions to achieve the desired effect—the project aims to provide a generic (yet efficient) compiler-based solution for SPM management that should require no more extra hardware other than a DMA engine. The advantages of such a compiler-based approach include i) improved programmability: software develops can write their code as if hardware caching is provided, so that they can focus on their core which eventually speeds up the development cycle. ii) enhanced portability: the same application code can be reused on different versions or even different SPM-based architectures, with slight attunement of the compiler. iii) simplified hardware design: processor designers can design simple yet power-efficient manycore processors with proper compiler support. Other than the readily perceivable merits, there is another subtle yet decisive reason for choosing compiler-based approaches: iv) delivery of comparable or even better application performance than hardware caching. With deliberately designed compiler analyses, we can greatly reduce the overhead incurred by SPM management (transferal of values between the SPM and main memory) in applications. Below is the general flow of our SMM compiler.
Looking ahead, while the bandwidth of communication between the local and global memory will increase, the memory latency will only increase with time. What is needed is a scheme that will cause small number of coarse-grain communications between the global and local memory. Also if the scheme cannot be automated, it should require a small number of intuitive changes in the application.
Resources