

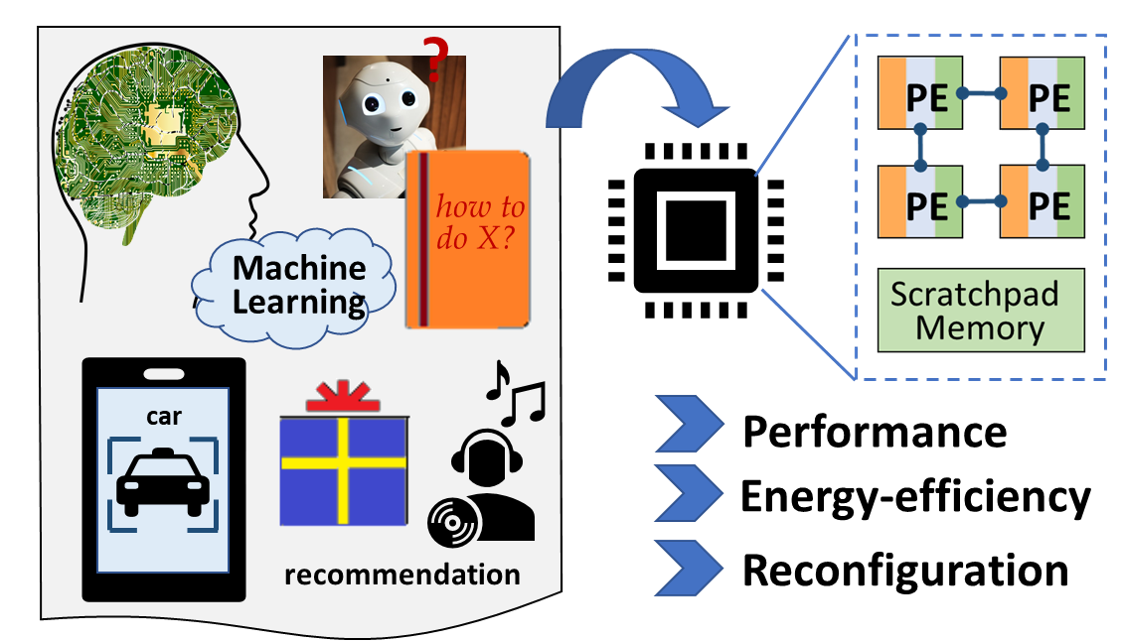
Machine Learning Accelerators
Machine learning models are becoming quite a norm of bringing the smartness in the system. For example, deep neural networks (DNNs) are widely used in several important domains including image recognition, object detection, media generation, and video analysis. However, their computation and memory requirements are doubling at every few months. Hence, the challenge that we as computing system architects, developers, and application designers face today is scaling the performance and energy-efficiency of the execution for the current and emerging workloads. In the “new golden age of computer architecture”, recent research efforts and commercial solutions have extensively demonstrated that the domain-customized accelerators significantly speed-up the execution in an energy-efficient way. More specifically, coarse-grained reconfigurable dataflow accelerators (CGRAs) have been repeatedly shown as very effective for domain-specific accelerations, including for machine learning, high-performance and scientific computing, and graph processing applications.
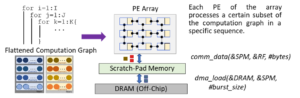
Dataflow accelerators are promising because they feature simplicity, programmability, and energy-efficiency. They comprise of an array of processing elements (PEs) with private register files (RFs) and a shared scratchpad memory (SPM). Since PEs are much simple in design (function units with little local control, as compared to out-of-order processing of a core), and the scratchpad is non-coherent, these accelerators are a few orders of magnitude power-efficient than CPU or GPU cores. Private and shared memories of PEs enable very high reuse of data, and through efficient data management, PEs can be engaged in continuous computations while data is communicated via memories. Thus, with minimized execution time, dataflow accelerators yield very high throughput and low latency. Following section summarizes some of our recent research explorations.
Challenges and Further Opportunities
Hardware-Software-Algorithm Co-design: For compute- and memory-intensive models, the vast space of accelerator design options combined with numerous loop-mappings onto their architectures, present significant optimization opportunities. For example, convolution layers of DNNs feature 7-deep nested loops, which enables many ways of the data reuse and spatial execution. Thus, it opens up many implementation choices for architecture design including sizes of PEs, RFs, SPM, and for each design, many ways to execute the loops both spatially and temporally onto the computational and memory resources of the accelerator. Since the experts often consider only certain ways of execution (like output-stationary or row-stationary dataflow mechanisms), they end up exploring only a tiny fraction of the space, during manual optimizations or randomization-based explorations. These ”execution methods” significantly impact computation and communication patterns, and therefore, have a dramatic impact on the energy consumption and execution time. So, it is crucial to optimize the execution method for any layer of a machine learning model and accelerator designs for multiple models. In the era, where the new models are being developed at a drastic rate, an effective and automatic solution can offer quick and systematic exploration for their efficient acceleration.
Model Compression: Programmers and accelerator designers can opt for improving the acceleration further by exploiting opportunities such as data sparsity (i.e., significant fraction of the tensor data is zero, which does not need to be stored or processed), data redundancy (tensor data elements share the value or approximated to alike values by clustering), data quantizations (lowering the precision of the data), and tensor decomposition. However, processing the tensor data on accelerators cannot automatically leverage such opportunities, and require special logic (and often changes in the software — loop-mappings, tensor data layout and format) that can handle compressed data for yielding such extremely lower computation and storage. Therefore, recent research have proposed solutions that can avoid or minimally process zeros in the tensors, or process approximated data. However, existing solutions (particularly for processing the sparse tensors) do not exploit the opportunities at the fullest. Moreover, accelerator designs or their codesigns with compilation or algorithm explorations is required, which can provide accelerations of tensors or models featuring varying levels of density on the same accelerator architecture. Furthermore, a few application domains (e.g., recommendation systems) present very high sparsity (e.g., less than 1% of the tensor data elements are non-zeros). Therefore, it opens opportunities of developing efficient co-designs of accelerators (or even accelerator-aware neural network search) and an in-depth analysis of performance implication for accelerator’s dedicated logic that facilitate processing of the compressed data. Our recent survey paper highlights such challenges and recent techniques for hardware acceleration of sparse, irregular-shaped, and quantized tensors.
Virtulization: Coarse-grained reconfigurable dataflow accelerators can be emulated on FPGA for testifying the functionality, and for validating performance optimizations at an extent. Moreover, recent research explorations have demonstrated that such designs can be suitable for programming FPGAs, since the compilation and execution takes place at a coarse-grain (e.g., word-level) vs. bit-level programming and design explorations for FPGAs. Thus, the virtualization can make it easier for using FPGAs and improves programmer productivity. It can also enable opportunities for emulating functionalities of accelerator designs and exploring feasibility of deploying coarse-grained programmable dataflow accelerators for different tensor applications. Furthermore, an open-source system stack, which can provide execution and exploration flow from machine or deep learning applications to the target accelerator architecture is much required, which can be a kick-starter for the community researchers, opening up doors for quick explorations of further opportunities and advanced co-designs.
Preliminary Research and Early Results
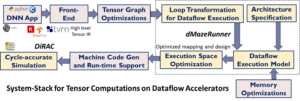
We have developed dMazeRunner framework which optimizes execution of compute-intensive and memory-intensive loops of DNNs for their dataflow acceleration. dMazeRunner formulates a holistic representation of the mapping-space that succinctly captures various loop-optimizations and dataflows (various ways of executing loops on dataflow accelerators). Then, dMazeRunner employs analytical energy and performance models that explicitly and accurately capture the computation and communication patterns, data movement, and data buffering of the different execution methods. Finally, dMazeRunner drastically prunes the search for optimizing mapping-space and design-space of these accelerators for ML models. Using TVM environment, dMazeRunner provides integrated support for optimizing dataflow acceleration of MXNet and Keras models. Our experiments on various convolution layers of popular deep learning applications demonstrated that for a 256-PE accelerator, the solutions discovered by dMazeRunner outperform previously proposed dataflow optimization schemes for the accelerators, and are on average 9× better in Energy-Delay-Product (EDP) and 5× better in execution time. With additional pruning heuristics, dMazeRunner reduced the search time from hours or days to just a few seconds with a mere 2.56% increase in EDP, as compared to the optimal solution obtained by its brute-force search.
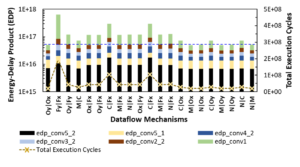
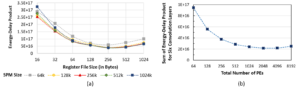 Figure: For various convolution layers of ResNet-18 model: (a) Design space exploration (DSE) of memory sizes for a 256-PE accelerator. (b) Optimizing accelerator designs by varying total PEs and sizes of memories.
Figure: For various convolution layers of ResNet-18 model: (a) Design space exploration (DSE) of memory sizes for a 256-PE accelerator. (b) Optimizing accelerator designs by varying total PEs and sizes of memories.
We have also alpha-released DiRAC, which is a microarchitecture template and simulator for dataflow acceleration of dense tensor computations. For DiRAC, programmers can specify different kernel functionalities, schedules for architectural executions, and architecture variants of the accelerator, and can observe performance implications. Users can specify architecture variations of the accelerators in terms of PE grid layout, PE pipeline, size + buffering + partitioning of register files and scratchpad memory, and configurations for interconnect and direct memory access (DMA). DiRAC allows to simulate acceleration of any nested loops which feature multiply-and-accumulate operations and no conditional statements. Thus, it enables users to learn about how dataflow accelerators work, how to validate their execution method (mappings) onto the accelerator with cycle-level details, while providing a reconfigurable accelerator template (instead of building such a design from scratch), and easy prototyping and sensitivity analysis of the accelerator design features.
Acknowledgement: This research is partially supported by funding from National Science Foundation and NSF/Intel joint research center for Computer Assisted Programming for Heterogeneous Architectures (CAPA). We gratefully acknowledge support from the sponsors and collaborators. Any opinions, findings, and conclusions presented in this material do not necessarily reflect the views of the sponsoring agencies.
- Reading Resources
- Software Downloads:
1. dMazeRunner – dataflow optimization for DNN accelerators
2. DiRAC – cycle-level simulator of reconfigurable dataflow accelerators - Relevant Publications