

 Need for faster and power-efficient processors has paved the way for many-core processors along with considerable research in accelerators. Acceleration through popular Graphics Processing Units (GPUs) is over a broad range of the parallel applications but majorly limited to massively parallel loops and loops with high trip counts. Field programmable gate arrays (FPGAs) on the other hand, are reconfigurable and general-purpose but are marred by low power efficiency due to their fine-grain management.
Need for faster and power-efficient processors has paved the way for many-core processors along with considerable research in accelerators. Acceleration through popular Graphics Processing Units (GPUs) is over a broad range of the parallel applications but majorly limited to massively parallel loops and loops with high trip counts. Field programmable gate arrays (FPGAs) on the other hand, are reconfigurable and general-purpose but are marred by low power efficiency due to their fine-grain management.
Coarse-Grained Reconfigurable Arrays (CGRAs) are promising accelerators, capable of accelerating even non-parallel loops and loops with lower trip-counts. They are programmable yet, power-efficient accelerators. CGRA is an array of Processing Elements (PE) connected through a 2-D network; each PE contains an ALU-like Functional Unit (FU) and a Register File (RF). FUs are capable of executing arithmetic, logical or even memory operations. At every cycle, each PE gets an instruction from the instruction memory, specifying the operation. The PE may read/write the data from/to data memory; data/address bus are shared either by PEs in the same column or by PEs in the same row. CGRA can achieve higher power efficiency due to simpler hardware and intelligent software techniques. [A Short Video on Executing the Loops on CGRA]
Challenges
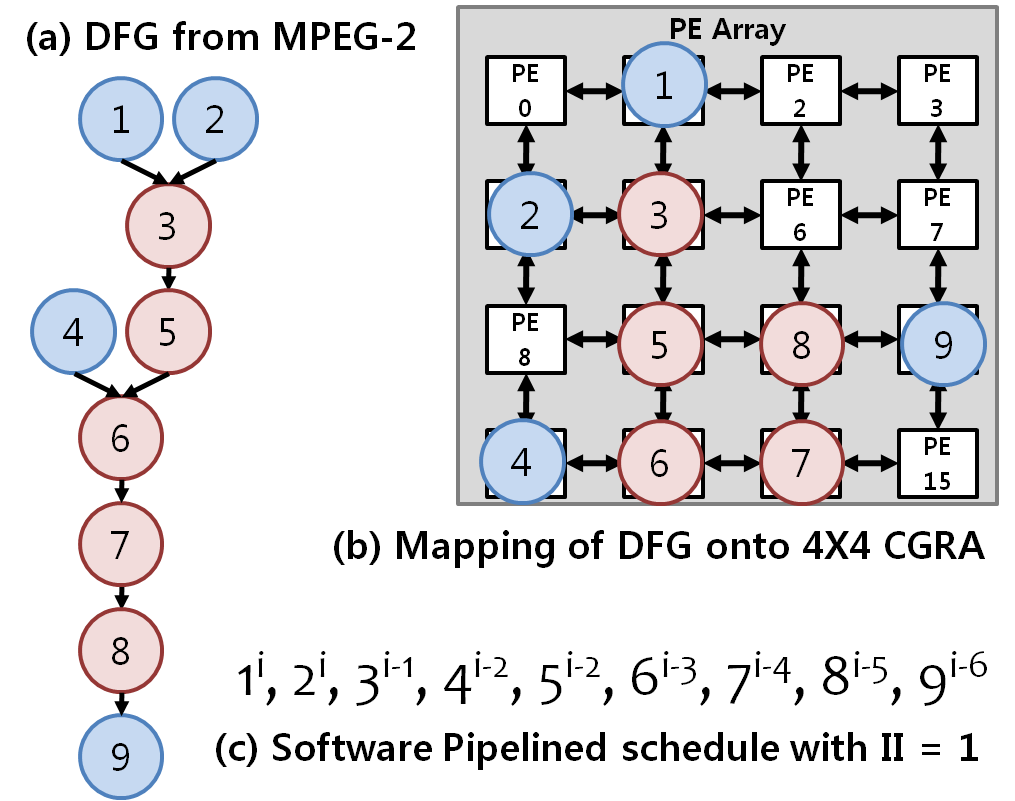
 Since CGRA is a simple hardware and all the intelligence and hence the complexity, has been transferred to the software, the compiler should be smart enough to effectively utilize the CGRA resources. One of the widely researched topics in CGRA research is the mapping techniques for CGRAs. Loop to be accelerated is extracted from the application and converted into a Data Dependency Graph (DDG). Problem formulation of the mapping of the DDG onto the target array is NP-complete. Plus, mapping hueristic should be able to generate the mapping with better quality in lower compilation time, as well as it should ensure maximum the usage of the CGRA resources — such as registers, PE units etc.
Since CGRA is a simple hardware and all the intelligence and hence the complexity, has been transferred to the software, the compiler should be smart enough to effectively utilize the CGRA resources. One of the widely researched topics in CGRA research is the mapping techniques for CGRAs. Loop to be accelerated is extracted from the application and converted into a Data Dependency Graph (DDG). Problem formulation of the mapping of the DDG onto the target array is NP-complete. Plus, mapping hueristic should be able to generate the mapping with better quality in lower compilation time, as well as it should ensure maximum the usage of the CGRA resources — such as registers, PE units etc.
Another major challenge in compiling for CGRAs is to accelerate the loops with the conditionals. Naive approaches can result in an inefficient usage of the resources and limited power-efficiency. Other challenges are accelerating nested loops, enabling multi-threading on CGRAs, efficient management of CGRA registers and memory-aware mapping for CGRAs.
Apart from compilers, CGRA architecture poses some significant challenges as well. Efficient management of CGRA registers, pertaining to the scalability of the CGRA is a challenge. Moreover, data memory bottleneck restrains the acceleration gains and has gained focus from the community. Designing the memory hierarchy for CGRA accelerators and the way of sharing the data between both the CPU core and the accelerator are the major challenges. Finally, unavailability of a common CGRA simulator platform inhibits the researchers to explore the architecture and discover new schemes for improvement. Such core+CGRA platform is necessary to see the applications accelerated through novel solutions and to validate the functionality accurately.
Our Approach
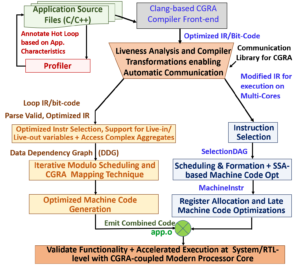
CGRA Compilation and simulation Framework (CCF) is an open source framework platform being developed for CGRA research and consists of LLVM and Gem5 tools as a foundation. CCF has an clang based compiler frontend for loop identification and extraction, and a set of analysis and transformation passes to generate DDG of the loops and to communicate the live data between CPU and CGRA accelerator. Once the compute-intensive loop is extracted and DDG is generated, the mapping algorithm maps the DDG on to the target CGRA architecture and then corresponding machine instructions to configure the CGRA PEs are generated. The executable can be simulated on the heterogeneous platform of CGRA accelerator coupled to a CPU, and it is modeled in the gem5. To boost the research on CGRAs, CCF development is open source and available for download.
CCF uses a resource aware mapping scheme (RAMP), which generates precise formulation for the CGRA mapping problem. The problem is formulated as one of finding a constrained maximal clique on the product of two graphs — the DDG of the loop, and the CGRA resource graph. In contrast to the previous ad-hoc problem definitions, our problem formulation is quite general and systematically and flexibly explores the various routing options. RAMP explicitly models different choices of routing the data dependencies through CGRA architectural feature (e.g. routing through PEs, distributed register files, spilling to memory etc). Based on the failure analysis, our method determines which routing strategies to explore, in order to map the operations. RAMP iteratively and constructively solves the problem, until a valid mapping can be found.
Apart from exploring the mapping heuristics, our prior research has tried to address other compilation and architectural challenges for CGRAs. Path selection based branching combines the operations from both – if and else path into the fused nodes in DDG, instead of the previous predication based techniques. It issues instruction only from the path taken by the branch at run time; alleviating predicate communication overhead. Similarly, memory aware mapping techniques can provide conflict-free scheduling for larger CGRAs using multibank memory with arbitration.