

Challenges
With higher performance and better power efficiency, GPU (Graphics Processing Unit) has enabled so-called ‘supercomputing to the masses’. However, the complex memory hierarchy and various architectural details introduced many optimization rules that make optimizing GPU programs very difficult. Our objective is to enable compiler to find the design choices that lead to better performance and to optimize accordingly.
Rise of GPU Computing


As a simple extension to C, CUDA has made programming GPUs so much easier than before. This simple and easy programming model, as well as outstanding performance and power/cost efficiency, popularized GPGPU (General Purpose computing on GPUs), and now GPU is considered as one of the most successful and promising computer architectures for the future.
Memory-Aware Compilation for GPU
Even though to start writing GPGPU applications has become easy, optimizing programs to fully utilize GPU’s performance is very difficult yet. This is because of numerous optimization rules that come from various hardware details. Those performance considerations are mostly on memory access performance. As thousands of cores are accessing the memory concurrently, memory access performance often affects the performance of a program significantly. To optimize an application, the programmer should beware of all the performance considerations and be able to predict the possible impact on performance for each of different design decisions, such as thread block size, shared memory buffer size, or global/shared memory references.
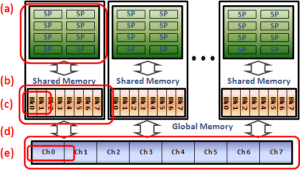
We aim to develop a compiler approach that can optimize a program to use memory in an efficient way. This should be first based on thorough analysis of all the performance-critical factors from the cores to the off-chip memory. Given a program and a set of design choices, the memory performance for each of design choices can be analyzed. Using this memory performance analysis, a compiler can explore design space, comparing the memory performance for each design choice, and optimize the program for better performance.
Relevant Publications