

Challenge
Code size is an important constraint for many embedded systems, especially the ones in which the code is burnt on ROMs, which can be the major component on the chip. Dual instruction set, one composed of full width instructions, and another composed of narrow instructions is a promising approach to reduce code size. Our research efforts are towards developing tools and techniques to compile for such reduced bit-width Instruction Set Architectures.
Partial Bypassing
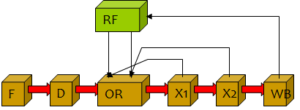
Bypasses or forwarding paths are simple yet widely used feature in modern processors to eliminate some data hazards. With Bypasses, additional datapaths and control logic are added to the processor so that the result of an operation is available for subsequent dependent operations even before it is written in the register file. Paths including the bypasses often are timing critical and add pressure on cycle time, especially the single cycle paths. The delay of bypass logic can be significant for wide issue machines. The situation is aggravated owing to the trend of long pipelines and high degrees of parallelism in modern processors. As a result, most processors can only afford some of the bypasses. The question is, which bypasses to have in the processor, so as to minimize the hardware overhead, but not loose too much performance as compared to a fully bypassed processor.
Bypass-Aware Compiler
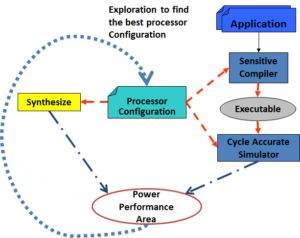
Determining optimal bypass configuration requires a true co-design effort in which both the layout effects and the compiler effects must be taken into account. The figure on the right shows a compiler-in-the-loop design methodology for exploring the bypasses in embedded processors. The bypass configuration is described in a text form in an architecture description language (in this case, EXPRESSION). We developed a bypass-sensitive compiler that reads the bypass configuration from the text file, and schedules instructions so as to avoid data hazards due to missing bypasses. We have also parameterized a cycle-accurate simulator to the bypass configuration. Further, we automatically generate the bypass control logic for the processor pipeline, and paramterize the RTL of the processor on the bypass configuration. For a given bypass configuration, the application is then compiled using the bypass-sensitive compiler, simulated on the cycle-accurate simulator to find the run-time, and the cycle-time, area, and power is estimated using the synthesized RTL. Different bypass configurations are explored to find the best bypass configuration.